
UIの裏側、巨大トラフィックとの対話。僕がフロントエンドではなく、SREの道を選んだ理由
今回は、情報工学科に在籍し、大規模トラフィックを扱うメガベンチャーでSREとして長期インターンをされているKentoさんにお話を伺います。Kentoさん、本日はよろしくお願いします!
Kentoです。よろしくお願いします。僕の話が、特にインフラやバックエンドに興味がある方の参考になれば嬉しいです。
ありがとうございます。早速ですが、多くの情報系学生がWebサイトやアプリの「見た目」を作るフロントエンドに興味を持つ中、なぜKentoさんはその裏側を支えるSRE(Site Reliability Engineering)やバックエンドの道を選んだのでしょうか?
はい。僕も最初は、多くの友人と同じようにReactを触っていたんです。でも、どうしても「面白い」と感じられなくて…。その理由を探求していくうちに、今の道にたどり着きました。
フロントエンド開発で感じた「物足りなさ」の正体
大学3年生の春、僕の研究室の友人たちは、こぞってReactやNext.jsを学び始めていました。
モダンなWeb開発のスタンダードであり、見た目が華やかなサービスをすぐに作れるフロントエンド技術は、確かに魅力的でしたね。
僕もその流れに乗って、チュートリアル動画を参考にしながら、いくつかのコンポーネントを組み立てて簡単なアプリケーションを作ってみたんです。
でも、正直なところ、何度やっても何か物足りない。
ユーザーインターフェース(UI)が形になっていく「高揚感」よりも、どうも「このUIの裏側で、データがどう動いているんだろう?」とか、「APIを叩いたときに、データベースのどんな状態が変わるんだろう?」っていう、より深い部分への興味が勝ってしまう自分に気づいたんです。
友人たちがUIのデザインやアニメーションの話で盛り上がっている横で、僕の頭の中は「この処理、もっと効率的なアルゴリズムがあるんじゃないか?」とか「このAPIレスポンス、本当にこのデータ構造が最適なのか?」とか、ひたすらユーザーの目には直接触れない、システムの「骨格」の部分にばかり関心が向いていました。
例えるなら、美しい絵画を鑑賞するよりも、その絵の具の化学成分やキャンバスの織り方、つまり「どうやって作られているか」を分析してしまうような感覚に近かったですね。
この、僕がフロントエンドの道に進まなかった最初の大きな違和感こそが、今のSREへの道の始まりだったんです。
「ネットワーク論」が僕のエンジニア人生を180度変えた
そんなモヤモヤを抱えていた僕にとって、決定的な転機となったのが大学の「ネットワーク論」の授業でした。
それまでのプログラミングとは一線を画す、全く新しい世界がそこに広がっていました。
TCP/IPの3ウェイハンドシェイク、膨大なリクエストを振り分けるロードバランサーの仕組み、そしてWebサイトの住所を解決するDNSのプロセス…。
普段僕たちが何気なくブラウザでWebサイトを見ている、その根幹を支えるあまりにも巨大で、そして精緻なシステムが目の前に現れたんです。
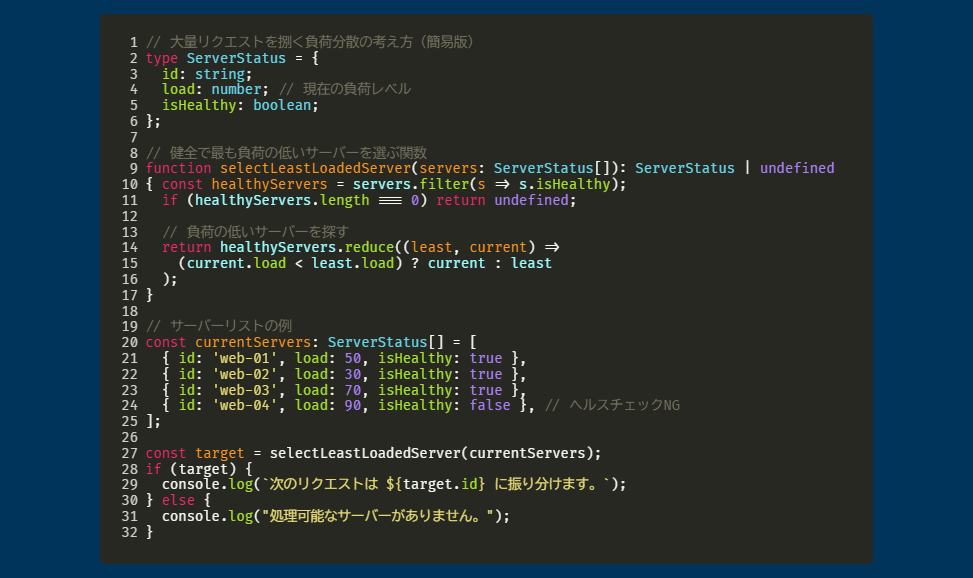
中でも特に衝撃を受けたのは、「いかにして膨大なリクエストを、たった数ミリ秒の遅延もなく、安定して捌き切るか」というテーマでした。
これって、美しいUIを設計するのとは全く違う、まさに知的な挑戦に満ちた世界だと直感しましたね。
僕が普段やっているフロントエンド開発だと、ユーザー側の体験に直結する「速さ」や「使いやすさ」は意識するけど、その裏で何十万、何百万のリクエストがどう流れて、どう処理されてるかなんて、ほとんど意識してなかったですから。
この講義を受けて、「これだ。僕が本当にやりたいのは、この巨大なパズルを解くことだ」と心底思いました。
目に見える部分を「作る」のではなく、目に見えないシステムの「挙動を最適化する」こと。
そこにこそ、僕の探究心や論理的思考力が最も活かせる場所があると感じたんです。
その瞬間から、僕の学習のベクトルは、完全に変わりました。
それまでReactとかJavaScriptばかり追っていたのが、Go言語やデータベースの内部構造、そしてAWSやDockerといったインフラ技術へと、もう180度完全にシフトしましたね。
フロントエンドエンジニアから見たSREの「面白さ」
僕自身、Web系自社サービス企業でフロントエンドエンジニアとして働いているからこそ、Kentoさんの話はすごく深く共感できるんです。
ReactやNext.jsって、本当に「すぐに動くものを作れる」高揚感があって、すごく楽しい技術ですよね。
でも、Kentoさんの言うように、その裏側にある「なぜ動くのか」「どうやって安定稼働しているのか」って部分にまで興味を持つ学生って、意外と少ないかもしれません。
フロントエンドから見ると、ユーザーが「表示が遅い」と感じる原因って、実はバックエンドやインフラ側にボトルネックがあることって結構あるんですよね。
JavaScriptの最適化をどれだけ頑張っても、APIのレスポンスが遅ければ意味がない。
だからこそ、Kentoさんの選んだSREという道は、サービス全体のパフォーマンスや信頼性を根本から支える、まさに「縁の下の力持ち」であり、めちゃくちゃ重要な役割だと感じます。
ユーザーから見える部分を作るフロントエンドと、その見えない部分を支えるSRE。
両者は全く違う職種だけど、サービスの成功というゴールに向かっては密接に繋がっている。
Kentoさんが「パズルを解く」と表現したように、目に見えない巨大なシステムを効率的に動かすっていうのは、フロントエンドで綺麗なUIを作るのとはまた違った、知的好奇心をくすぐる面白さがありますよね。
もし今、フロントエンドを触ってて「なんか違うな」と感じてる学生がいたら、Kentoさんのように、一度視点を裏側に広げてみるのはすごく良い選択肢だと思います。
- 大学3年生 春フロントエンド開発で感じた「物足りなさ」
多くの友人がReactやNext.jsに触れる中、自身も簡単なフロントエンドアプリを開発。しかし、「UIの裏側でデータがどう動くか?」「APIのデータ構造は?」といった、システムの「骨格」への興味が勝り、フロントエンドに物足りなさを感じる。
- 大学3年生 春〜夏「ネットワーク論」との出会い、SREへの転換点
大学の「ネットワーク論」の授業が転機に。TCP/IP、ロードバランサー、DNSといった、巨大なシステムを安定稼働させる仕組みに強い探究心と面白さを感じる。「目に見える部分を作る」より「目に見えないシステムの挙動を最適化する」ことに魅力を感じ、学習のベクトルがSRE・バックエンドへ完全にシフト。**学習をシフトした技術領域**
- Go言語
- データベース内部構造
- AWS
- Docker
- 大学3年生 夏〜メガベンチャーでのSRE長期インターン開始
大規模トラフィックを扱うメガベンチャーのSREチームで長期インターンを開始。マイクロサービスの複雑性、Docker/Kubernetesによる管理、そして「たった一行のコードがサービス全体を止めるかもしれない」という強烈なプレッシャーを体感。CI/CDパイプラインの重要性を肌で学ぶ。**インターンで経験した主な技術・ツール**
- Go言語
- Docker
- Kubernetes
- CI/CDパイプライン
- Slack (通知連携)
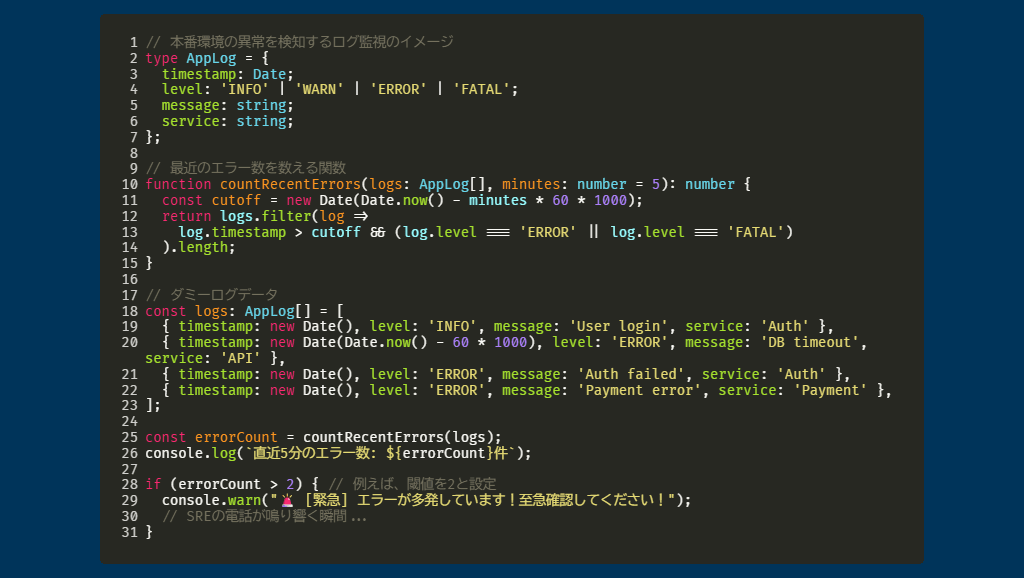
- インターン中盤監視と改善の実践、パフォーマンスチューニング
「APIレスポンスのスパイク原因調査と改善」というミッションを担当。Grafanaで監視グラフを分析し、Prometheusのメトリクスを元に仮説検証。PostgreSQLのクエリ最適化(インデックス改善)により、数十ミリ秒のレスポンスタイム改善を達成。「目に見えない改善」がサービスの信頼性を築くことを実感する。**業務で深掘りした技術・ツール**
- Grafana (監視ダッシュボード)
- Prometheus (メトリクス収集)
- PostgreSQL (データベース)
- クエリ最適化
- ログ分析
- 現在・今後SREとしての展望と後輩へのメッセージ
「サービスの根幹を支えている」というSREのやりがいを強く感じる。将来の目標として、「フレームワークの前に基礎を学ぶこと(HTTP、OS、DB構造、ネットワーク)」、「CUIと友達になること(Vim、grep、awk、ssh、AWS CLI)」、「エラーログを読むことを楽しむこと」の3つを後輩に伝える。**Kentoさんが考えるSREの重要スキル**
- コンピュータサイエンスの基礎知識(HTTP, OS, DB構造, ネットワーク)
- CUI操作スキル (Vim, grep, awk, ssh, AWS CLI)
- エラーログ読解力
本番環境の洗礼。数百万人が使うサービスの裏側で戦うということ
なるほど…。自分の「面白い」と感じるポイントに正直になった結果、今の道を見つけたのですね。そこからSREチームでの長期インターンに参加されたわけですが、実際の現場はいかがでしたか?大学の授業とは、やはり違いましたか?
全くの別物でしたね。正直、最初の1ヶ月は、自分が宇宙に来てしまったのかと思うくらい、何も分かりませんでした。特に、システムの規模と複雑さには圧倒されました。
「宇宙に来たみたい」って、なんだかすごく分かります(笑)。僕も最初の現場はそうでしたね。具体的に、どんな点で「規模と複雑さ」を感じたんですか?例えば、扱うサーバーの数とか、連携するサービスの多さとか…?
まさにその通りです。サーバーの数もそうなんですが、一番驚いたのは、開発環境がすごく整っていたことです。大学の研究室でちょっと触るような規模とは全然違って、CI/CDもきっちり組まれていて。あと、ログの量もすごくて、最初はどこから手をつけていいか全く分かりませんでした。
「たった一行」がサービスを止める強烈なプレッシャー
インターン初日、メンターの社員さんに見せてもらったのは、まさに目が眩むようなマイクロサービスの全体構成図でした。
何百というサービスが、それぞれ独立して動き、互いにAPIで通信している。
その一つ一つがDockerコンテナとしてパッケージングされ、Kubernetesによって管理されている。
大学の演習で書いたモノリシックなアプリケーションとは、もう次元が違う複雑さでしたね。
そして、何よりも僕を震え上がらせたのは、「自分の書いたたった一行のコードが、この巨大なシステムのどこかに影響を及ぼし、数百万人が使うサービス全体を止めてしまうかもしれない」という、想像を絶するほどの強烈なプレッシャーでした。
正直、最初のうちはコードを書くのが怖くて仕方なかったです。
僕が普段書いているフロントエンドのコードだと、もしバグがあっても、せいぜいそのページだけが壊れるとか、最悪でもサービス全体が止まるってことはめったにありませんから。
SREの世界では、その影響範囲が段違いなんだと、初日からガツンとやられました。
最初に与えられたタスクは、あるサービスのログを監視して、特定のエラーが出たらSlackに通知するという、ぱっと見は小さなものでした。
でも、そのためにコードを書いてデプロイするまでの道のりが、信じられないほど長かったんです。
プルリクエストを出すと、CI/CDパイプラインが自動で動き出して、静的解析、単体テスト、結合テストが次々と実行される。
その後、レビューでOKが出たら、今度はステージング環境にデプロイされて、そこでQAが行われる。
全てのステップをクリアして、ようやく本番環境に反映される。
この一つ一つのステップが、巨大なシステムを安定稼働させるための「安全装置」なんだってことを、まさに肌で理解しました。
監視グラフが語る「数十ミリ秒」改善のドラマ
現場の圧倒的な規模と厳しさに打ちのめされながらも、メンターさんの手厚いサポートのおかげで、少しずつキャッチアップしていきました。
そんなある日、僕に一つの大きなミッションが与えられました。
それは、「あるマイクロサービスのAPIレスポンスタイムが、時々スパイク(突出)する原因を調査し、改善する」というものでした。
与えられた手がかりは、Grafanaで可視化された監視グラフだけ。
僕はまず、グラフの波形とひたすら睨めっこしながら、スパイクが発生する時間帯やリクエストの傾向を分析しました。
そして、Prometheusで取得された詳細なメトリクスを元に、「この処理が怪しいんじゃないか?」「ここで時間がかかっているはずだ」と、仮説を立てていきました。
仮説検証のために、Goで書かれたコードにいくつかログを仕込んで、本番のトラフィックの一部を流してその結果をまた分析する。
そんな地道な作業を、何日も何日も繰り返しましたね。
そしてついに、特定の条件下で発行されるPostgreSQLへのクエリが、インデックスをうまく使えておらず、極端に遅くなっている箇所を突き止めたんです。
メンターと相談してクエリを修正し、プルリクエストを提出。
承認を経て、本番環境にリリースされた数時間後、僕は再びGrafanaの画面を見ていました。
そこには、これまで不規則に跳ね上がっていたグラフが、まるで嘘のように平坦になっている様子が映し出されていました。
平均レスポンスタイムが、数十ミリ秒改善された瞬間でした。
もう、「やった…!」って、声には出しませんでしたが、心の中でガッツポーズしましたね。
「目に見えない改善」がサービスの信頼性を築く
Kentoさんの話を聞いて、僕が普段ReactやNext.jsでUIを触っていると、ユーザーの反応がダイレクトに返ってくることが多いんですが、SREの仕事って、本当に「目に見えない改善」の積み重ねなんだなと改めて感じましたね。
たった数十ミリ秒の改善って、ユーザーはまず気づかないでしょう。
でも、その小さな改善が、月間数千万、数億アクセスという巨大なトラフィックを捌くサービスの信頼性を根底から支えている。
この事実には、本当に胸を打たれます。
フロントエンドエンジニアがユーザーの「使いやすさ」や「体験」を追求するのに対して、SREはシステムの「安定性」や「効率性」という、より深い部分でユーザー体験を支えている。
Kentoさんが体験した「グラフの波形が平坦になる」瞬間って、きっとフロントエンドで新しい機能がリリースされて、ユーザーから「いいね!」って言われるのとはまた違った、エンジニアとしての深い達成感があるんだろうなと想像できます。
まさに、システムの「探偵」であり「守護者」ですよね。
僕も以前、ちょっとしたコードのミスで本番環境のリリースを巻き戻した経験があるんですが、Kentoさんの「たった一行のコードがサービスを止めるかもしれない」というプレッシャーは、本当に痛いほどよくわかります。
だからこそ、CI/CDパイプラインやテスト、コードレビューといった「安全装置」の重要性を、僕も日々痛感しています。
そういう仕組みを構築し、守っていくのがSREの役割なんだなって、改めてこの話で理解が深まりました。
「縁の下の力持ち」こそが、最高の仕事
すごい…。グラフの波形という、目に見えないユーザー体験の改善をやり遂げたんですね。まさに探偵のような仕事で、めちゃくちゃ面白いです。その経験を通じて、Kentoさんが考えるSREやバックエンドエンジニアの魅力って、どんなところにありますか?
やはり、「サービスの根幹を支えている」という実感が、一番の魅力だと思います。僕たちが手を抜けばサービスはすぐに不安定になりますし、逆に僕たちが頑張れば、サービスはより速く、より安定する。その責任の重さとやりがいは、何物にも代えがたいです。
責任とやりがい、ですね。最後に、これからKentoさんと同じように、バックエンドやインフラの道を目指す後輩たちに、何かアドバイスがあればお願いします。
偉そうなことは言えませんが、僕が意識してきたことを3つ、お伝えします。
一つ目:基礎の重要性
もし僕と同じように、バックエンドやインフラの道に興味がある学生がいたら、まず伝えたいのは「フレームワークの前に、基礎を学ぶこと」です。
これ、本当に大切なんです。
もちろん、ReactやNext.jsみたいに、バックエンドにもNode.jsのExpressやNestJS、GoのGinとかEchoとか、たくさんのフレームワークがありますよね。
これらの使い方は、正直、現場に入ってしまえば実践でガンガン覚えていけます。
でも、それよりも遥かに重要なのが、「なぜそのフレームワークが必要なのか?」を理解するための、コンピュータサイエンスの基礎知識なんです。
具体的に言うと、HTTPの仕様、OSがどう動いているのか、データベースの内部構造、ネットワークの仕組み(TCP/IPとかサブネットとか)…こういった知識をしっかり勉強してください。
僕もインターンで日々実感しているんですが、問題が起きたときに、フレームワークの機能だけ知っていても、根本原因にはたどり着けないことが多いんです。
そんな時に、コンピュータサイエンスの基礎知識が、まるで真っ暗闇で道に迷ったときの「地図」のように、問題解決の糸口を与えてくれます。
これは、どんな新しい技術が出てきても、決して色褪せることのない、エンジニアとしての真の武器になりますから。
二つ目:CUIとの親交
二つ目は、「黒い画面(CUI)と友達になること」ですね。
これはもう、インフラの世界では基本中の基本と言っても過言じゃないです。
初めてコマンドラインを見たときって、拒否反応を示す人も多いと思うんです。
「なんだか難しそう」「とっつきにくい」って。僕も最初はそうでした。
でも、例えばVimやEmacsといったテキストエディタを使って直接サーバー上でコードを書き換えたり、`grep`や`awk`みたいなコマンドを駆使して、数テラバイトあるログの中から特定のエラーだけを抽出して分析したり、`ssh`でリモートサーバーにログインしてデバッグしたりする。
こういった作業は、GUI(グラフィカルユーザーインターフェース)では絶対にできない、コマンドラインならではのパワフルな世界なんです。
最初は本当に大変で、簡単なコマンド一つ覚えるのも一苦労かもしれません。
でも、この「黒い画面」を使いこなせるようになると、もう作業効率が格段に上がりますし、何より、システムの深い部分にアクセスできるようになります。
僕が普段使っているAWSのCLIとかもそうですけど、コマンド一つでインフラを自在に操れるようになる感覚は、一度味わうと病みつきになりますよ。
まさに、エンジニアとしての「魔法の杖」を手に入れるようなものです。
三つ目:エラーログは最高の「ヒント」
そして三つ目は、これは僕がインターンで一番強く感じたことなんですが、「エラーログを読むことを楽しむこと」です。
エラーって、最初はどうしても「やばい、バグだ!」って焦って、目を背けたくなりますよね。
でも、実はエラーって敵じゃないんです。
システムが僕たちに送ってくれる、最高の「ヒント」なんです。
なぜこのエラーが出たのか、どのファイルの何行目で、どんな状況で発生したのか。
エラーログには、その問題解決に必要な情報が全て詰まっています。
まるで難解な推理小説を読み解くような面白さがあるんです。
僕もインターンで何度もエラーと格闘しました。
初めて直面するGoのエラー、PostgreSQLのクエリエラー、Kubernetesのエラーログ…。
最初は本当に意味が分からなくて、ただただGoogle検索に頼ってました。
でも、メンターさんに「エラーログをしっかり読んでごらん」って言われて、スタックトレースを一行ずつ追いかけたり、エラーコードの意味を調べたりするうちに、だんだんとシステムの「声」が聞こえるようになってきたんです。
エラーを恐れるのではなく、「システムが何かを伝えようとしているんだ」と、対話する相手だと考えてみてください。
きっと、今まで見えなかったシステムの内部挙動が、クリアに見えてくるはずです。
この感覚を掴めると、もうエラーは怖くなくなりますよ。
インタビュー後記
Kentoさん、本日は貴重なお話を本当にありがとうございました。
華やかなUIの裏側で、サービスの信頼性という根幹を支えるSREの仕事のリアルと、そこに懸ける熱い情熱に、僕自身もエンジニアとして襟を正される思いでした。
多くの学生がまず触れるであろうWebフロントエンドの世界。
そこで「何か違う」と感じたとしても、それは決してネガティブなことではない。
むしろ、自分の好奇心に正直になることで、Kentoさんのように、より自分にフィットした、奥深い世界への扉が開くのかもしれません。
特に印象的だったのは、「エラーログは、システムからのヒント」という言葉です。
うまくいかない時、つい目を背けたくなってしまうエラーの文字列。
しかし、それこそがシステムの挙動を理解するための最も雄弁なドキュメントであると捉える彼の姿勢に、プロフェッショナルとしての矜持を感じました。
TechRoidは、まさにKentoさんのような「リアルな体験談」を届けたいと常に考えています。
この記事が、情報不足や先行きの不安に悩むあなたの背中を、少しでも押すことができたなら幸いです。
Kentoさん、本当にありがとうございました。今後のご活躍を心から応援しています!

